前言
此前提到微天气应用程序需要使用到行政区划数据,不过上一章所使用的数据来源于网络,或多或少都可以考虑一下是否还有其他获取的方式,所以也就有了本文的内容。
在这里,将基于全国1:100万基础地理信息数据进行行政区划数据的提取。本文用于记录使用程序实现全国1:100万基础地理信息数据合并的全过程。
当然,本文产生的最重要原因其实并不是受到微天气的启发,更多的是个人想试一试能不能用。
数据说明
全国1:100万公众版基础地理信息数据(2021)覆盖全国陆地范围和包括台湾岛、海南岛、钓鱼岛、南海诸岛在内的主要岛屿及其临近海域,共77幅1:100万图幅,该数据集整体现势性为2019年。数据采用2000国家大地坐标系,1985国家高程基准,经纬度坐标。
为满足广大社会群众对地理信息数据资源的需求,经自然资源部授权,全国地理信息资源目录服务系统提供全国1:100万全图层要素免费下载的服务。下载数据采用1:100万标准图幅分发,内容包括水系、居民地及设施、交通、管线、境界与政区、地貌与土质、植被、地名及注记9个数据集,且保存要素间空间关系和相关属性信息。
💡 提供下载的是矢量数据,不是最终地图,与符号化后的地图再可视化表达上存在一定差异。用户利用此数据编制地图,应当严格执行《地图管理条例》有关规定;编制的地图如需向社会公开的,还应当依法履行地图审核程序。
成果规格
-
分幅编号及范围
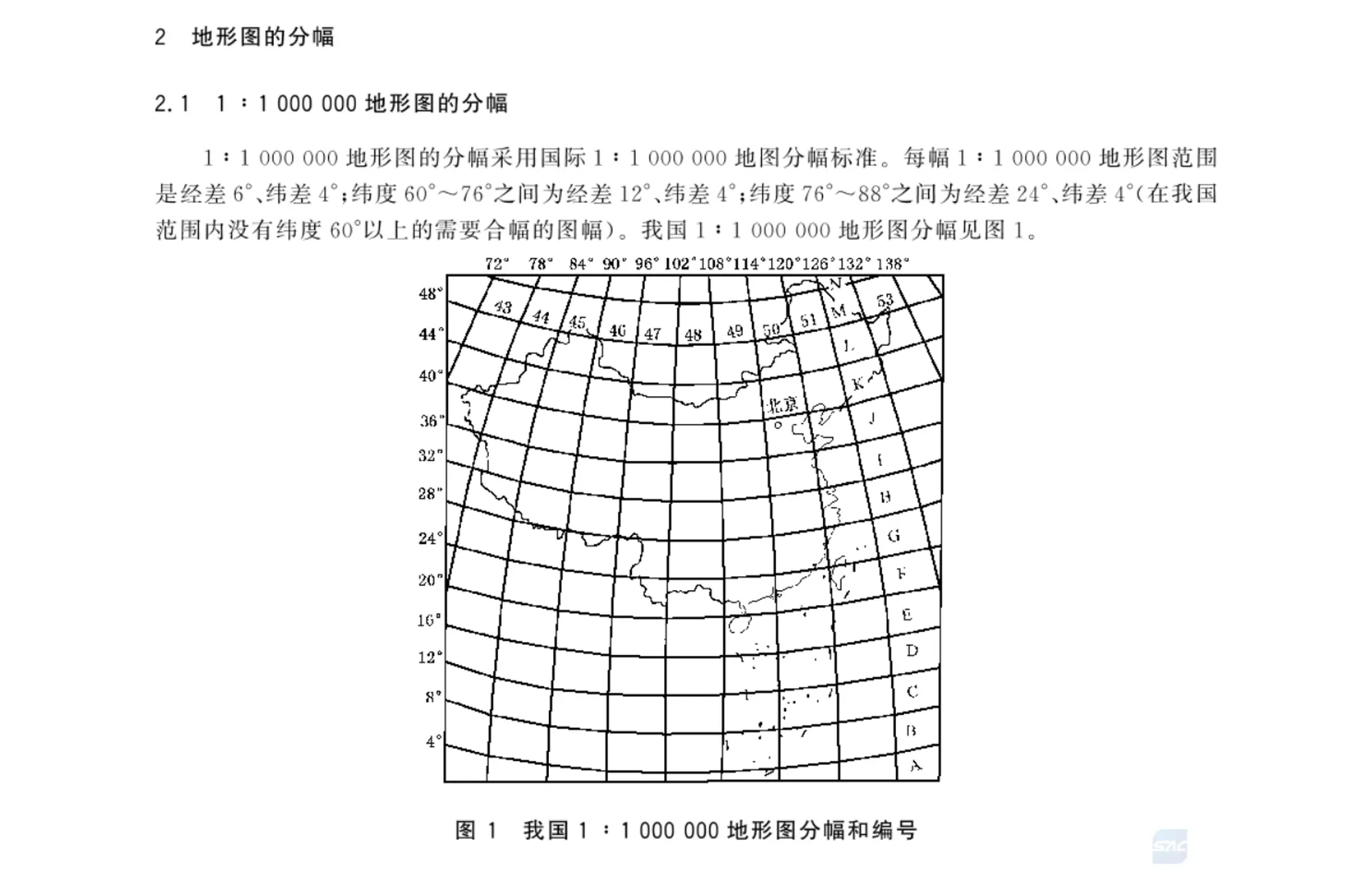
1:100万公众版基础地理信息数据(2021)的图幅总数为77幅,分幅数据按照GB/T 13989-2012《国家基本比例尺地形图分幅和编号》执行。空间存储单元为6°(经差)×4°(纬差)。
-
坐标系统
- 平面坐标系: 2000国家大地坐标系。
- 高程基准:1985国家高程基准。
- 地图投影:分幅数据采用地理坐标,坐标单位为度。
-
几何精度
更新后地物点对于附近野外控制点的平面位置和高程中误差符合下表的要求,以两倍中误差值为最大误差。
地物点误差 最小 最大 平面位置 100 500 高程 50 200 -
现势性
1:100万地形数据现势性与更新使用的数据源的现势性一致,数据整体现势性达到2019年。
成果数据组织
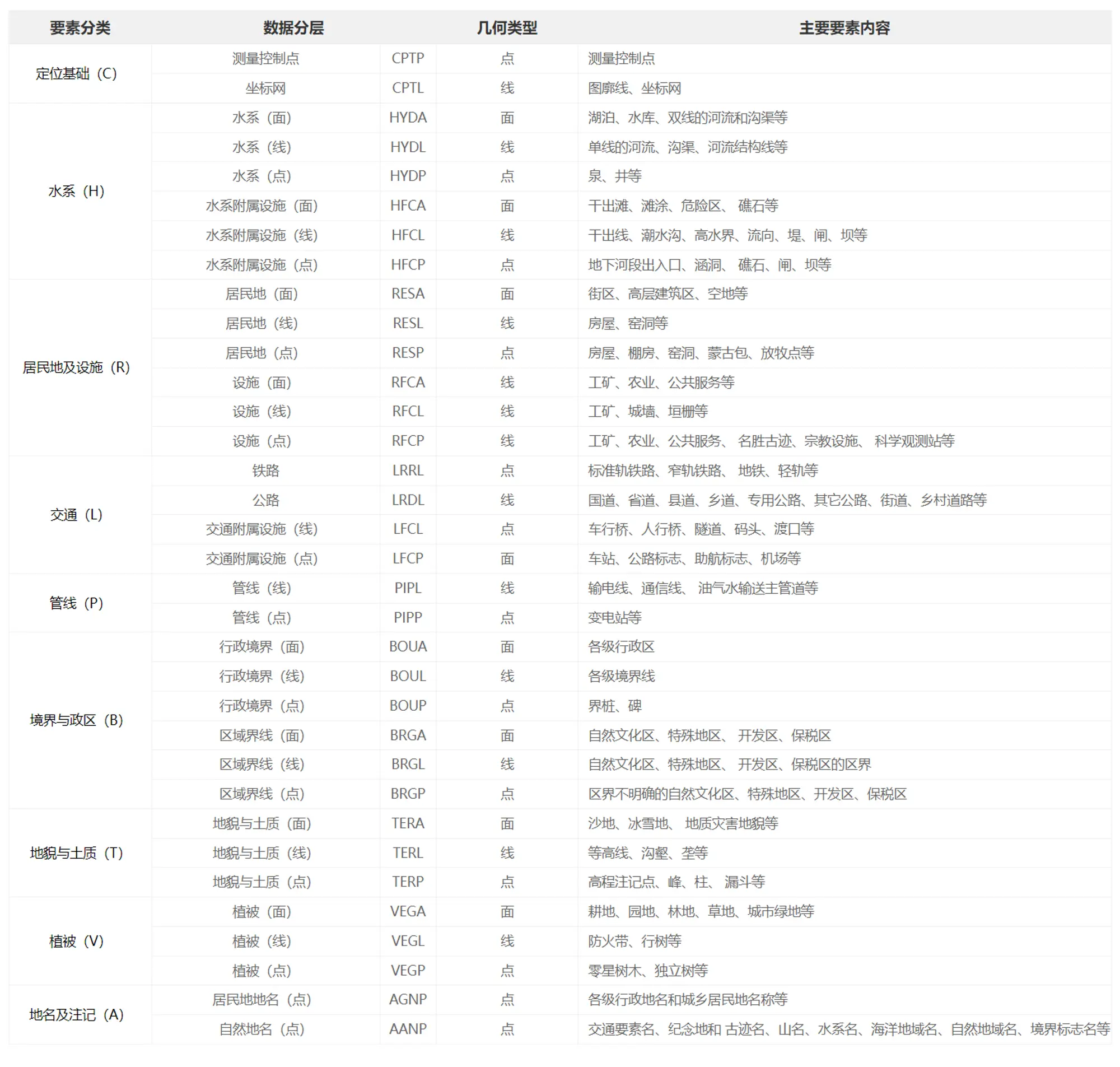
全国1:100万公众版地形数据(2021)内容包括水系、居民地及设施、交通、管线、境界与政区、地貌与土质、植被、地名及注记9个数据集。
数据分层的命名采用四个字符,第一个字符代表数据分类,第二三个字符是数据内容的缩写,第四个字符代表几何类型。
目标
- 实现分图层合并(处理图幅合并时接边问题)
- 水系(暂缓)
- 交通(暂缓)
- 境界与政区(国、省、市、县)
- 地名及注记
- 根据合并后的行政区划与地名注记,制作行政区划数据库
- 数据库使用PostgreSQL(PostGIS)
设计
图层解析程序
Java程序, 使用GDAL 读取GDB
逻辑
根据《国家基本比例尺地形图分幅和编号》规定可知网格范围,通过网格范围动态生成对应网格的分幅编号,并以该编号进行数据检索。如果命中则根据成果数据组织规格以及相关标准对数据进行解析,如果未命中则跳过,直至网格扫描完毕。
经度:72~138(E),43~53(11)
纬度:0~56(N),A~N(14)
即,网格范围:[43,53] x [A,N]
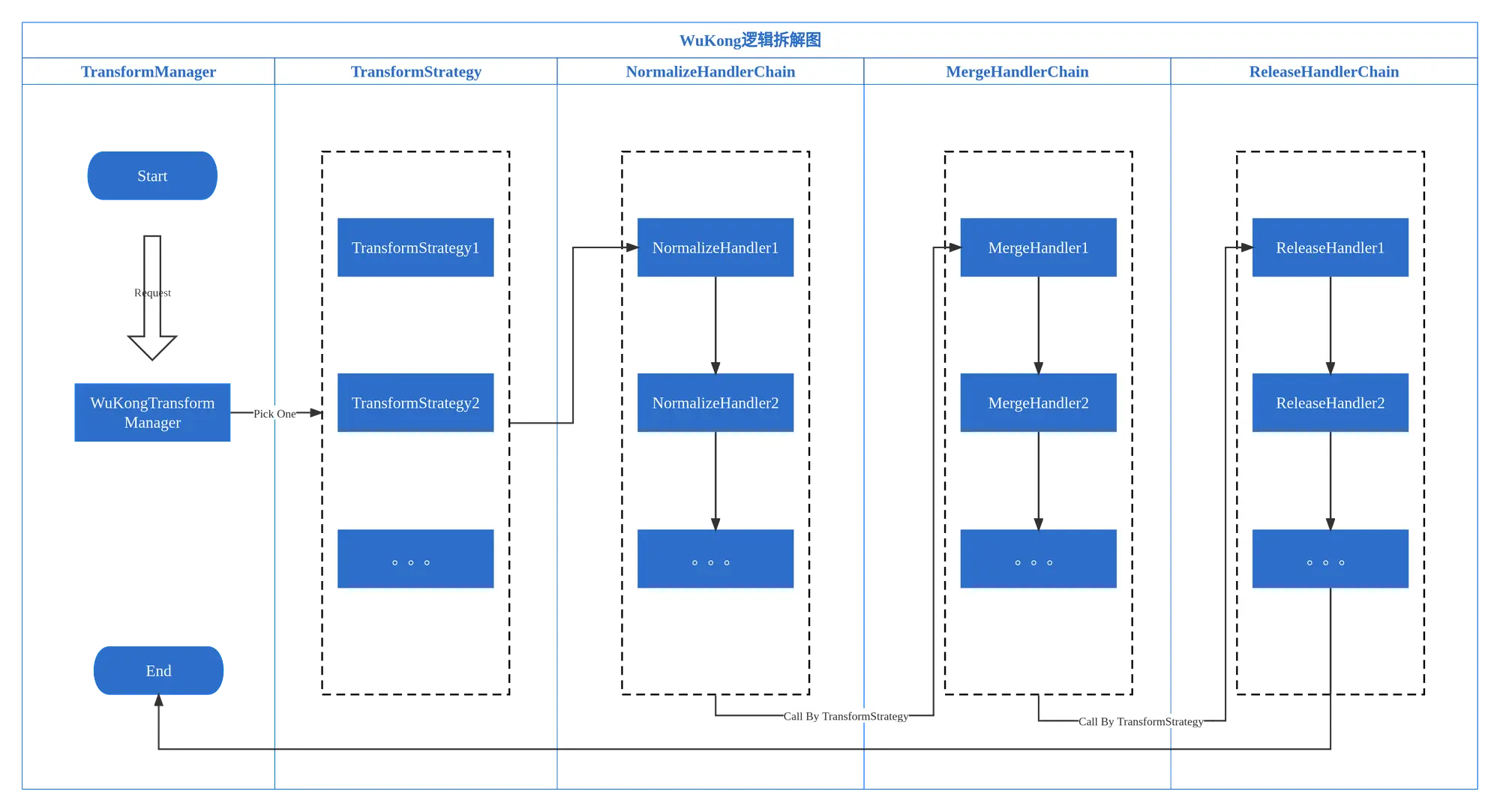
数据的处理流程可使用责任链模式进行,后续也方便加入其他的处理流程。即,整体的执行框架为策略模式+责任链模式。为统一策略选择模型,在此提出图层定义(LayerDefinition)的概念。
LayerDefinition由如下几个关键要素组成:
- 图层数据源(LayerSource)
- driver:驱动,参考java.sql.UnWrapper实现
- instance
- name
- catalog:
- schema:
- table:
commonDefinitionKey:常规定义缓存的keyfieldDefinitionKey:字段定义缓存的keyfeatureCarrierKey:要素载体缓存的key
- driver:驱动,参考java.sql.UnWrapper实现
- origin:数据来源(分幅文件路径)
- scale:比例尺(如:1000000,表示1:1000000)
sourceSpatialRef:源坐标系(表现形式可为标准ID、PROJ Text、WKT Text)sinkSpatialRef:目标坐标系(表现形式可为标准ID、PROJ Text、WKT Text)featureCode:要素分类码,对应成果数据组织中的要素分类(如:C、B)- name:图层命名,也是图层分类码
- layerCode:图层分类码
- release:释放格式(比如:WMTS、Shapefile、GDB…)
描述字符为:比例尺:源坐标系:目标坐标系:要素分类码:图层名称:释放格式,在描述字符串中,坐标系仅使用标准ID表示
💡 源坐标系、要素分类码、图层名称均来自于源数据。当且仅当原始数据中无法获取到源坐标系定义时,源坐标系定义可来自于配置。
基本流程
-
扫描网格定义(可配置)
-
GDB读取(支持zip,并推荐使用zip)
/home/fuyi/GeoDatabase/China_Basic_1-100/J50.gdb /home/fuyi/GeoDatabase/China_Basic_1-100/J50.gdb.zip -
策略管理器(StrategyManager),职责:根据配置选择具体策略方案,并调用执行
策略(Strategy),持有相应的处理器对象,责任链由此开始启动
总体上分为三个阶段
1、图层归一(数据、位置、坐标系) 2、图层合并 3、图层释放(service、dump、nothing) Layer normalization (data, location, coordinate system) Layer merging Layer release (service, dump, nothing)- 归一化处理阶段(应保证空间参考归一、图层数据存储归一,即应保持整体一致)
- 合并处理阶段(或者称之为中间处理阶段,在这里不仅可以处理合并,还可以做其他的事情)
- 释放阶段(数据的处理总归是有目的存在的,那么本阶段就是确定数据最终存在或服务的形式,比如导出为Shapefile文件、写入PostGIS数据库或通过WMTS服务对外提供数据访问等)
GDAL策略:默认策略,即全程基本上使用GDAL处理
-
匹配获取指定图层处理器(归一化),职责为:解析
先写缓存(redis)
- support(根据图层命名),如:
boua,该值作为处理器的判断条件
- support(根据图层命名),如:
-
可提供转换处理器,职责为:坐标系转换
坐标系转换既可以在归一化处理阶段进行(保证不同空间参考的数据转入同一空间参考),也可以在中间处理阶段(统一进行数据转换)或是释放阶段(根据释放需求进行处理)
-
提供数据合并处理器,职责为:跨图幅的图层合并
处理逻辑,根据给定的关联列进行空间对象合并(如:在行政境界中使用行政区划编码以及名称进行空间合并)
不同图层可以具有不同的合并规则,由不同的实例进行提供对应的合并行为
-
释放逻辑也通过定义格式处理器完成处理,职责:格式处理
- 需指明格式与比例尺
- support,根据格式与比例尺,如:
postgis:1000000,该值作为处理器的判断条件
-
不同比例尺创建不同的存储名称。如,存储格式为PostGIS:
表命名规则:图层名称_比例尺,小写
如:
boua_1000000,意为1:1000000比例尺下boua数据层数据
💡 LayerDefine结构可作为所有策略选择的入参,内部则根据自己依赖的条件进行决策。
Driver(register) → GDALDriverManager → DataSet → Layer → Feature → Geometry
Redis缓存作为转换过程中的数据存储与交换容器图层定义拆分为两个部分进行存储,常规内容使用hash结构存储,便于进行变更 prefix key : feature code : layer code : definition
scalesourceSpatialRefsinkSpatialRefstorage属性定义使用set结构存储,便于序列化与反序列化
prefix key : feature code : layer code : definition : fields
fieldDefinitions图层数据则使用list数据结构进行储存,便于序列化与反序列化,同时便于数据追加 prefix key : feature code : layer code : features
features
结构拆解图
开发
环境准备
- 操作系统:Debian 11 bookworm(testing)
- IDE:IntelliJ IDEA 2022.1.4 (Community Edition)
- PostgreSQL:14(13+即可)
- JDK:openjdk version “11” 2018-09-25
- Maven:Apache Maven 3.8.6
- GDAL:GDAL 3.5.1, released 2022/06/30
GDAL环境准备
debian 11 testing,自行编译gdal程序
/debian 11 testing,已经自行安装了gdal程序,但是没有java binding模块,所以还是需要自行编译。
我今天用的是Fedora 38 workstation,可以直接 install gdal, gdal-java,而后将libgdalalljni.so文件拷贝到/usr/java/packages/lib 目录下(如果不存在,请自行创建)
sudo mkdir -p /usr/java/packages/lib & sudo ln -s /usr/lib/java/gdal/libgdalalljni.so /usr/java/packages/lib/libgdalalljni.so
@time: 2023.10.08
异常
下图是经过pac,name合并后的数据(并去除了境外与海洋数据),如图可见,仍然存在些许裂缝
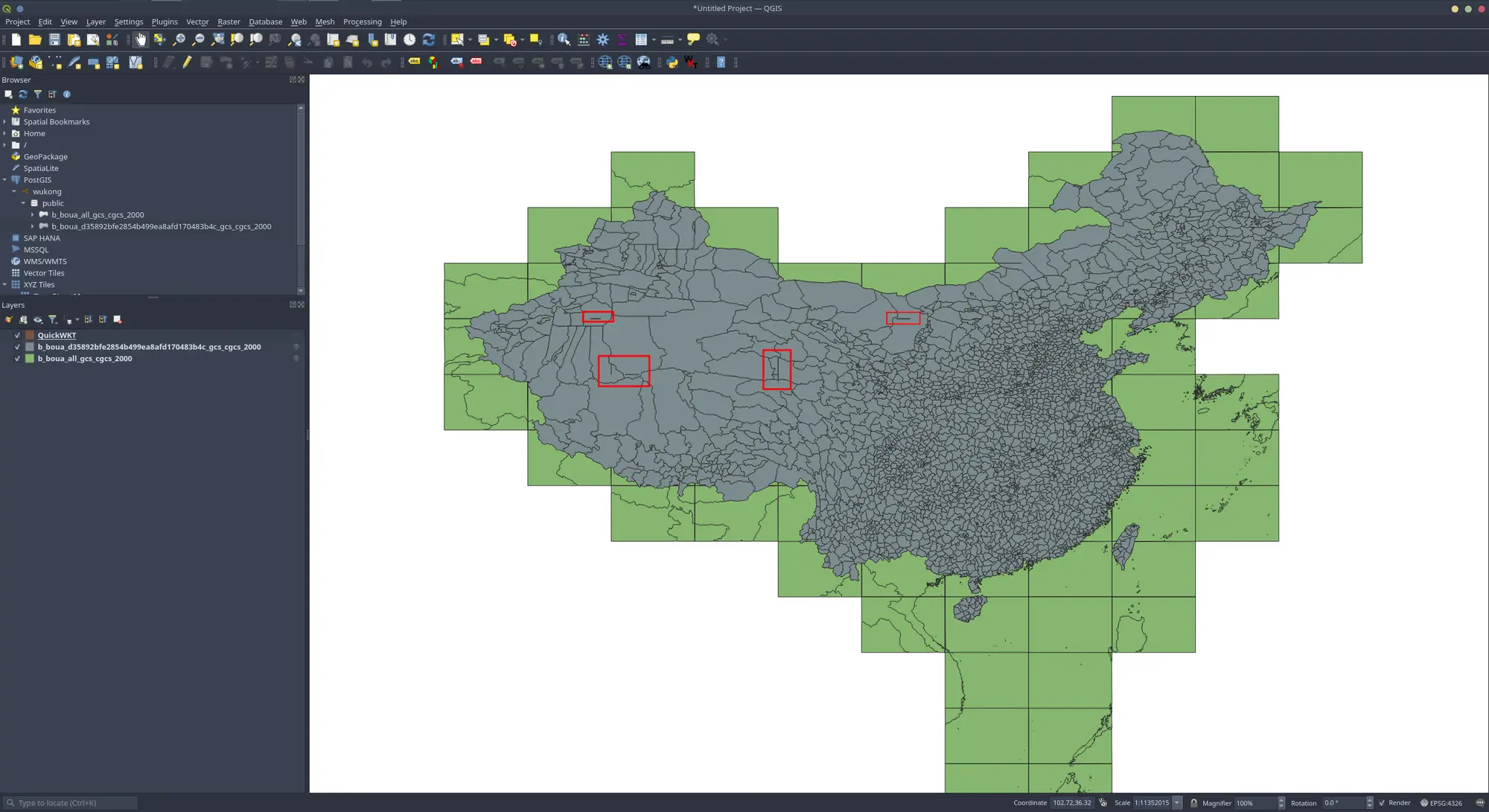
经过排查发现,发现部分原始图副之间便存在裂缝,且该裂缝的两边不一定是平行的。那么这就会导致合并出现两种情况
-
待合并的多边形之间存在裂缝,且多边形互相不相交
也就是隔海相望的那一种,此种情况是可以通过后续手段修复的,不过也是只有在裂缝的定义存在于合并后的多边形中(只不过可能被定义为洞)的情况下,如果不在的话,也不知道应该如何出来
-
待合并的多边形之间存在裂缝,且多边形存在相交,并且交点在裂缝之上
这种形式便不知道应该怎么处理了。
💡 感觉本质上,是一个找到裂缝的过程,并将裂缝作为内容的一部分进行合并。但是如何确定裂缝的范围也是不容易的,这可能和多边形间相互位置关系有关系
成果
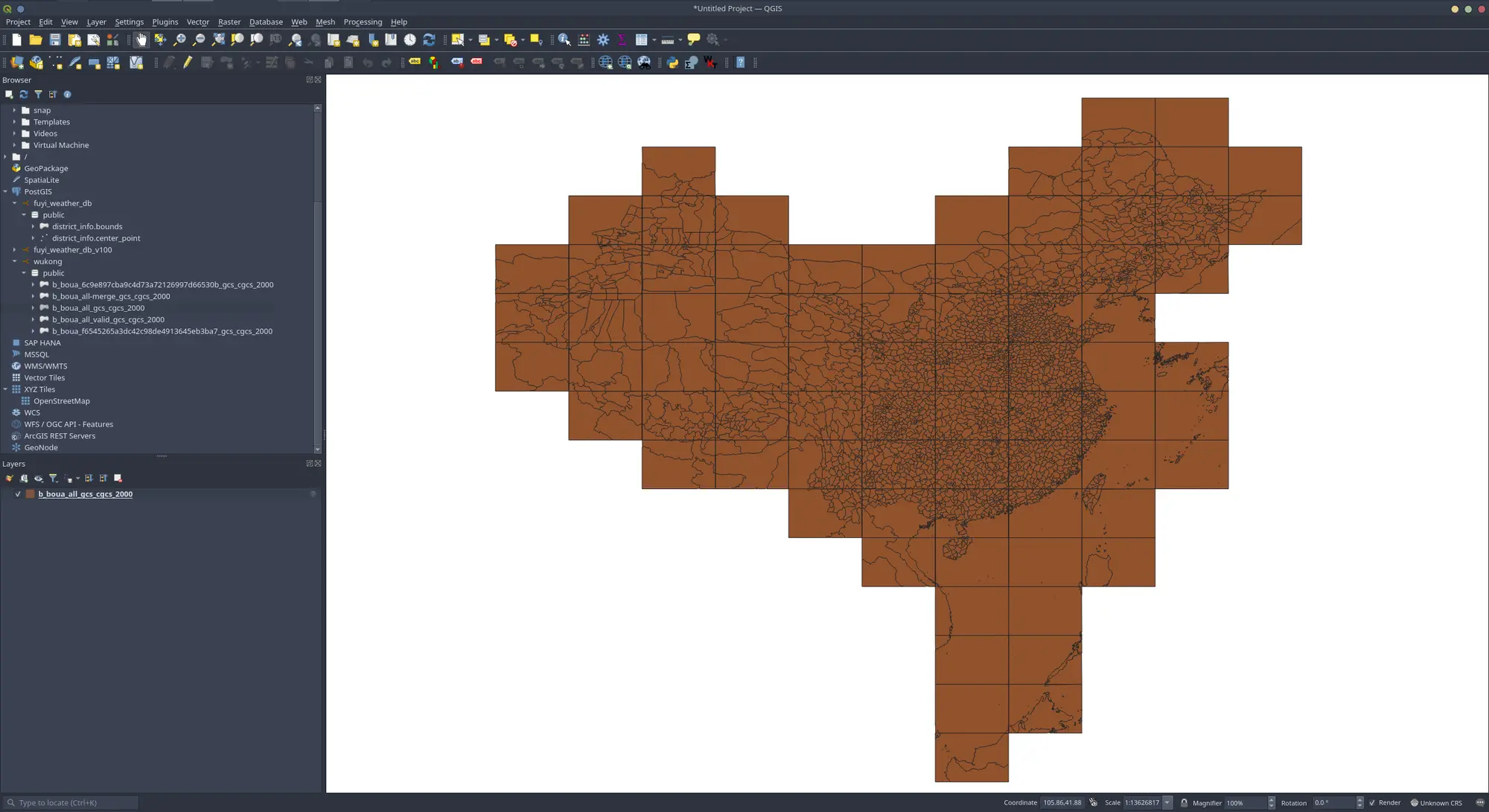
归一化
即将分离的图幅数据提取到统一位置存放,坐标本来就是统一的,不需要额外操作
去除无效区域与数据
- 去除境外数据(pac < 100000)
- 去除海域面数据(pac = 250100)
- 去除空间无效数据(
ST_IsValid(geometry)==false)
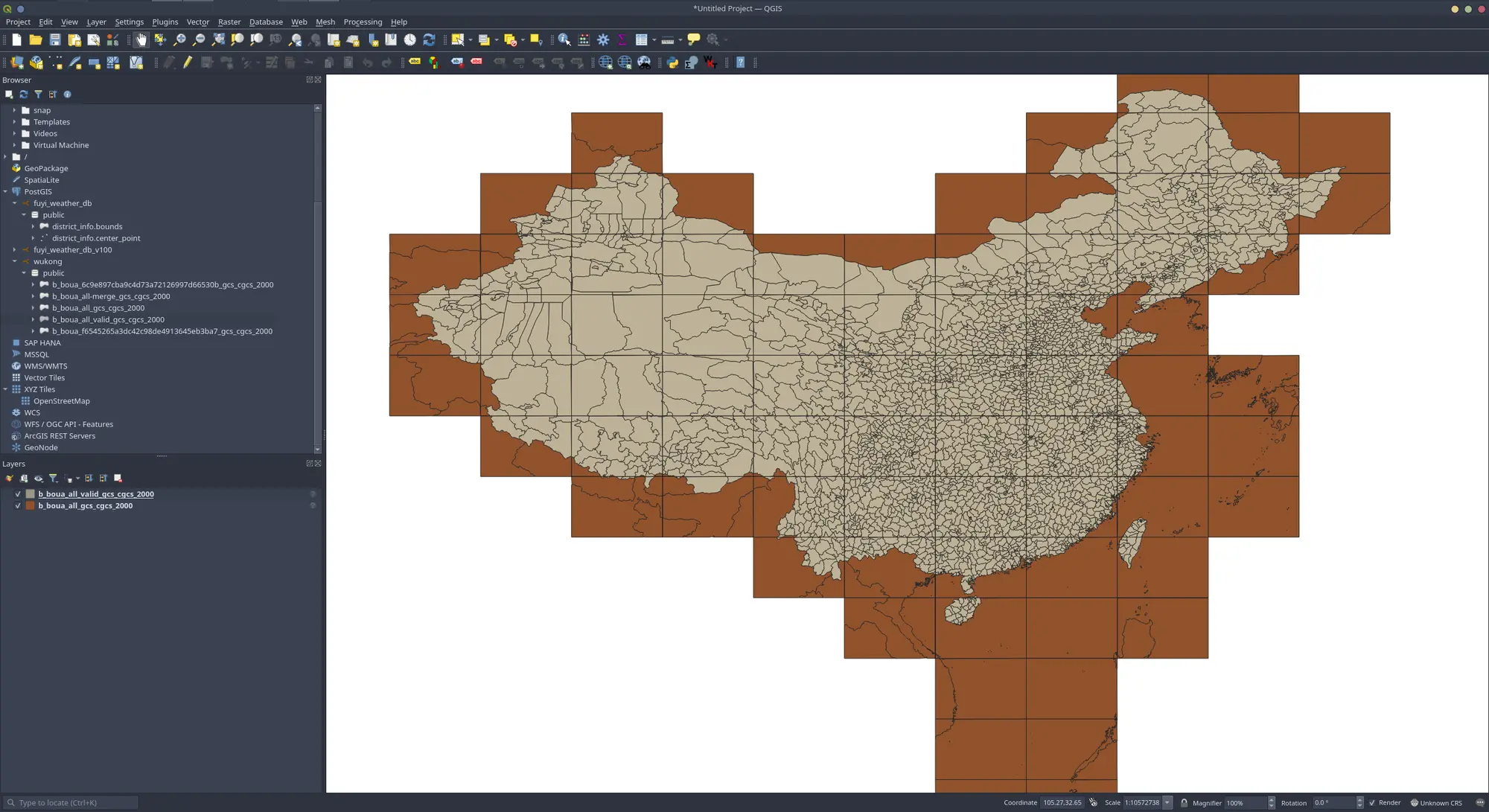
合并处理
即进行图幅合并(使用pac与name)
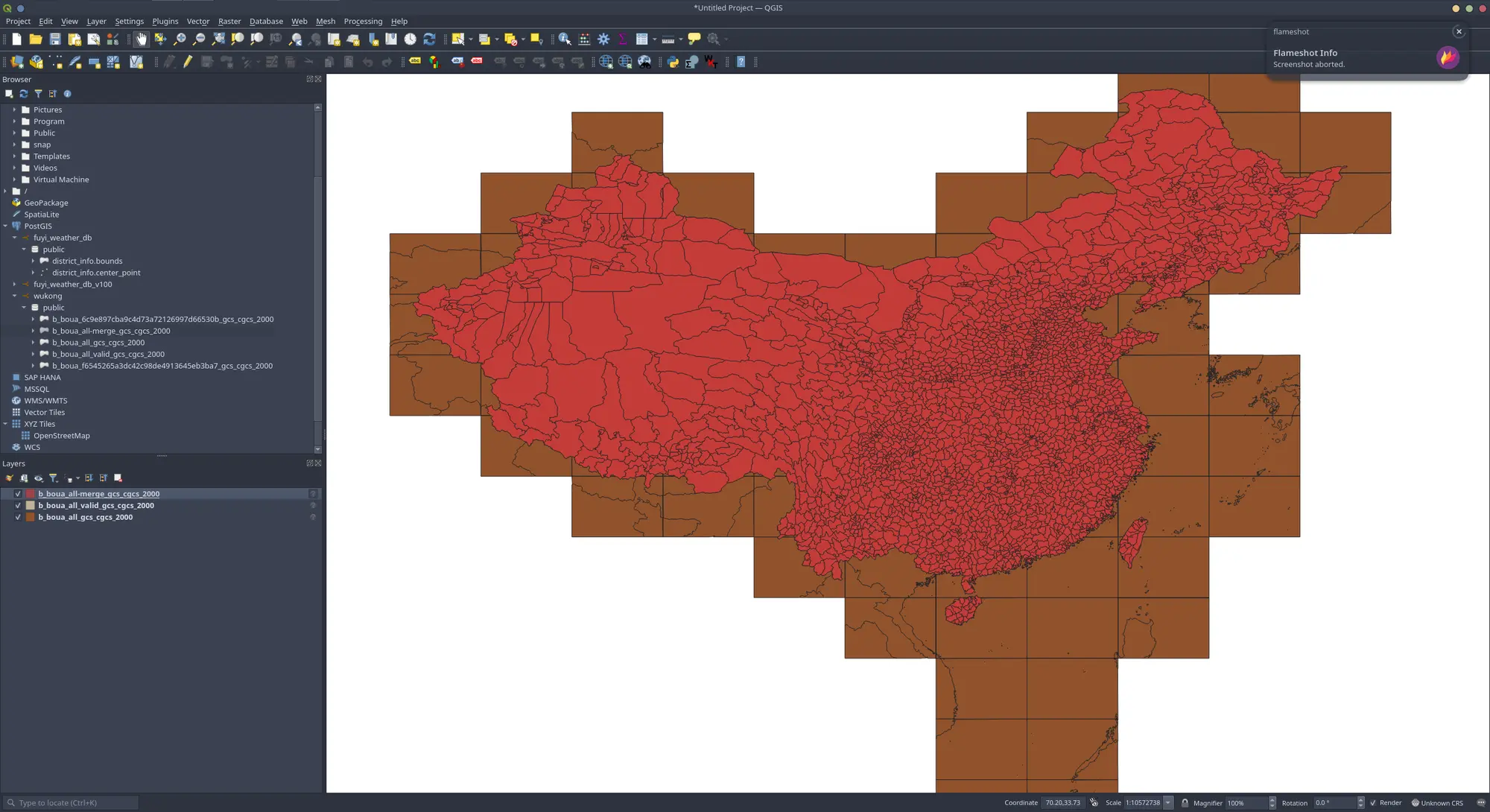
💡 从此处可以发现,部分区域存在裂缝。
1、pac=632722
2、pac=140404
3、pac=140427
4、pac=520625
5、pac=520628
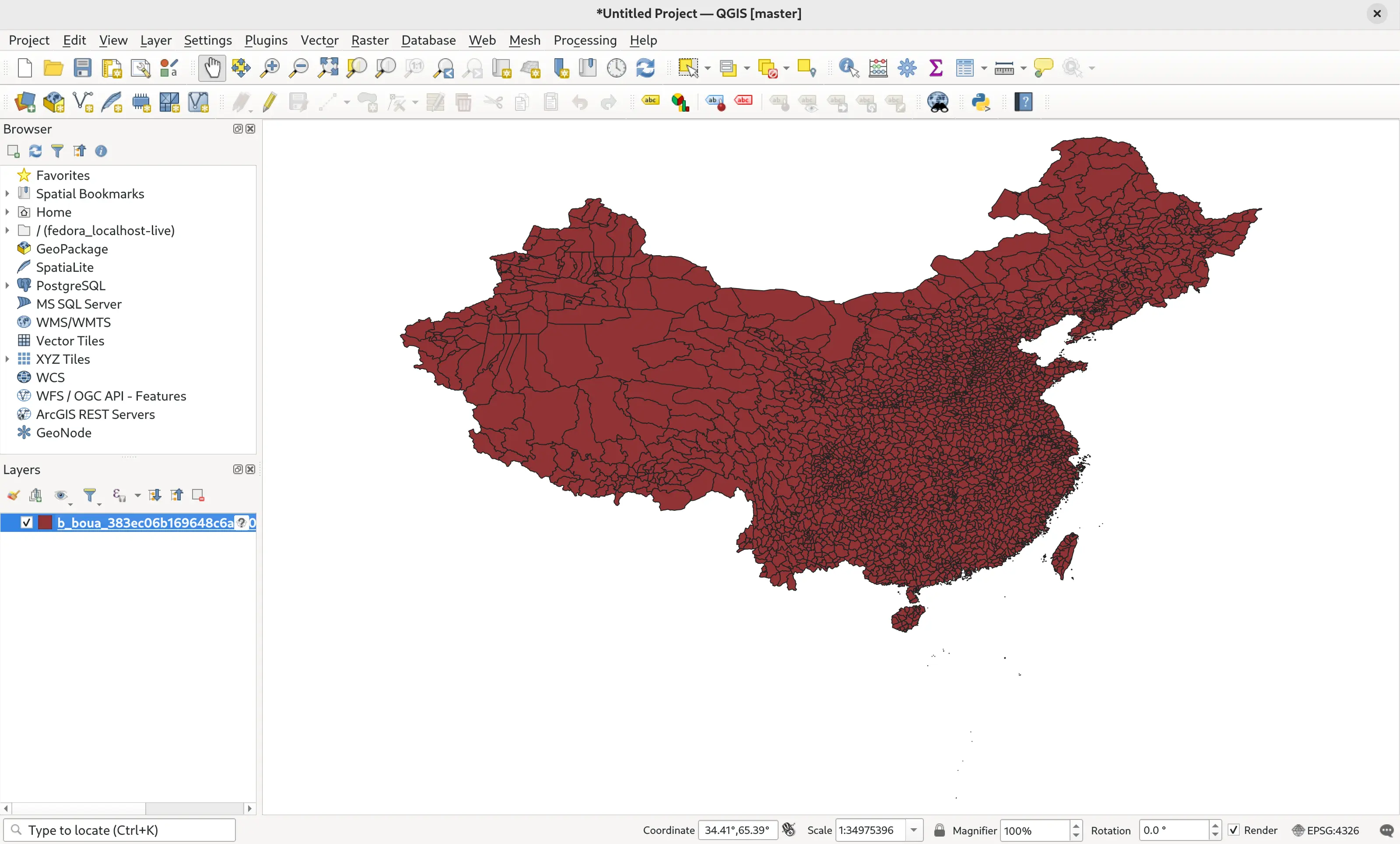
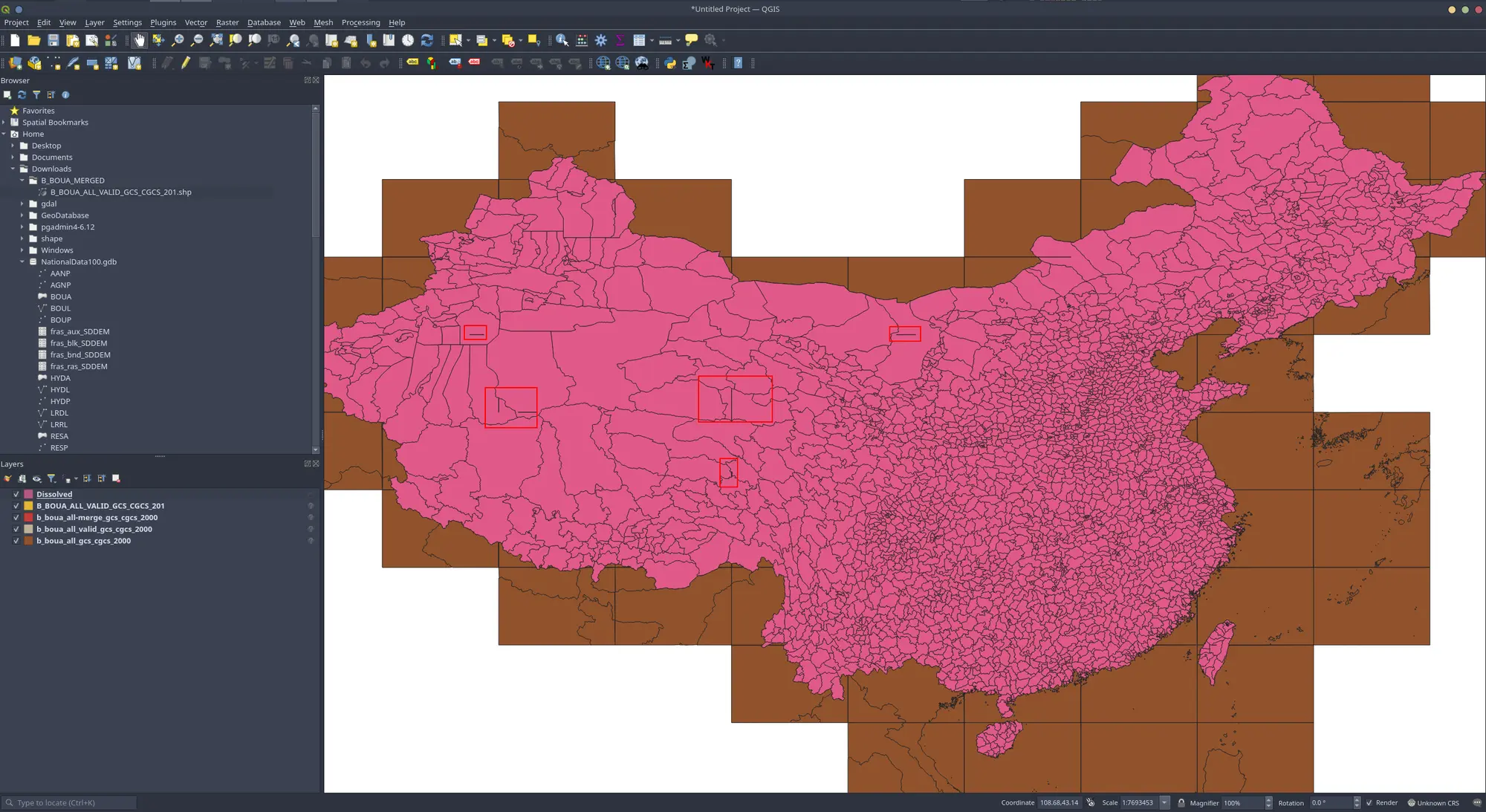
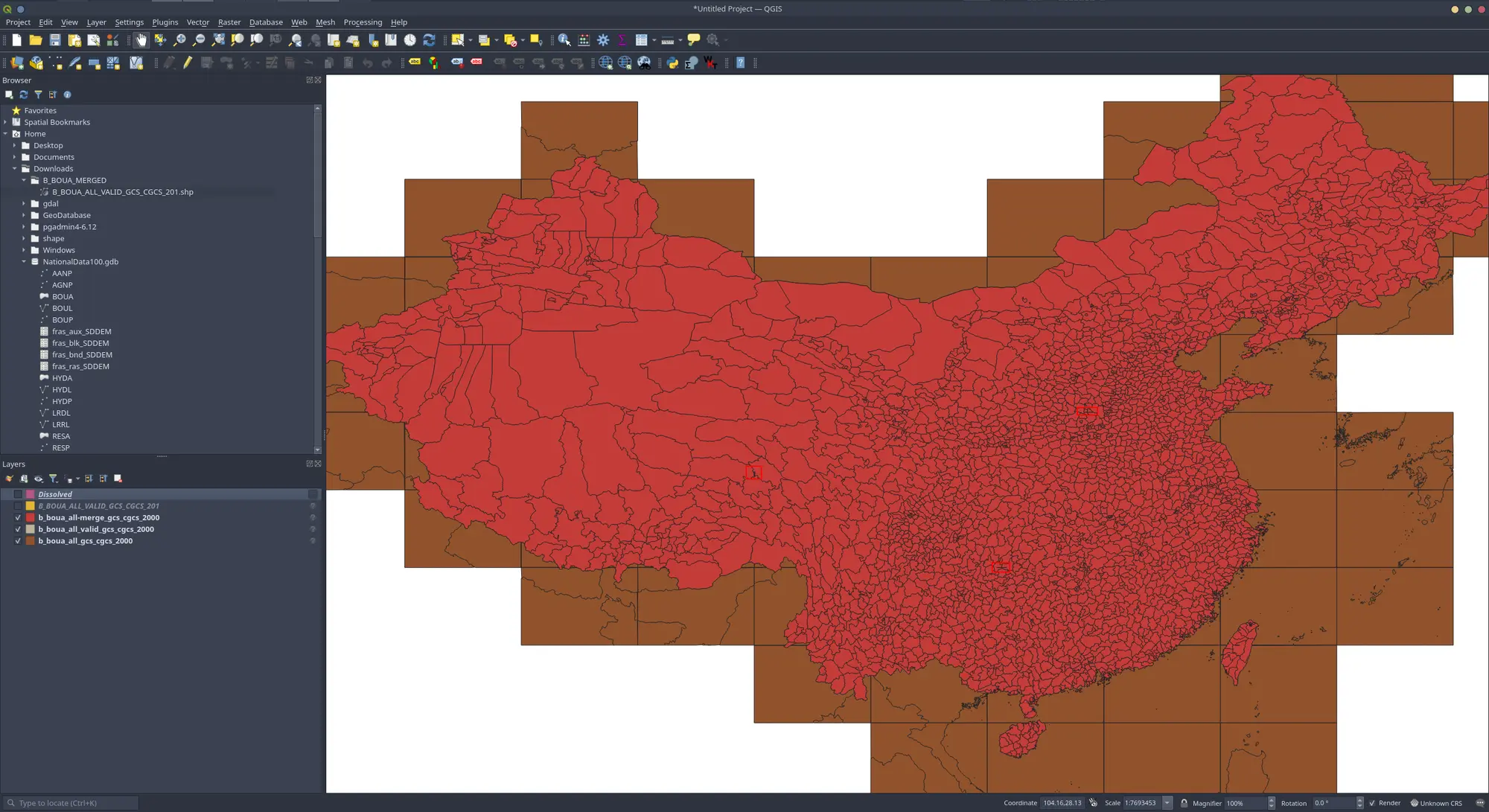
我同时对比了QGIS、ArcGIS中提供的Dissolve工具的融合效果(使用pac与name),就都存在裂缝情况上: 合并后的数量都是:2900arcgis 优于 wukong 优于 qgis
ArcGIS
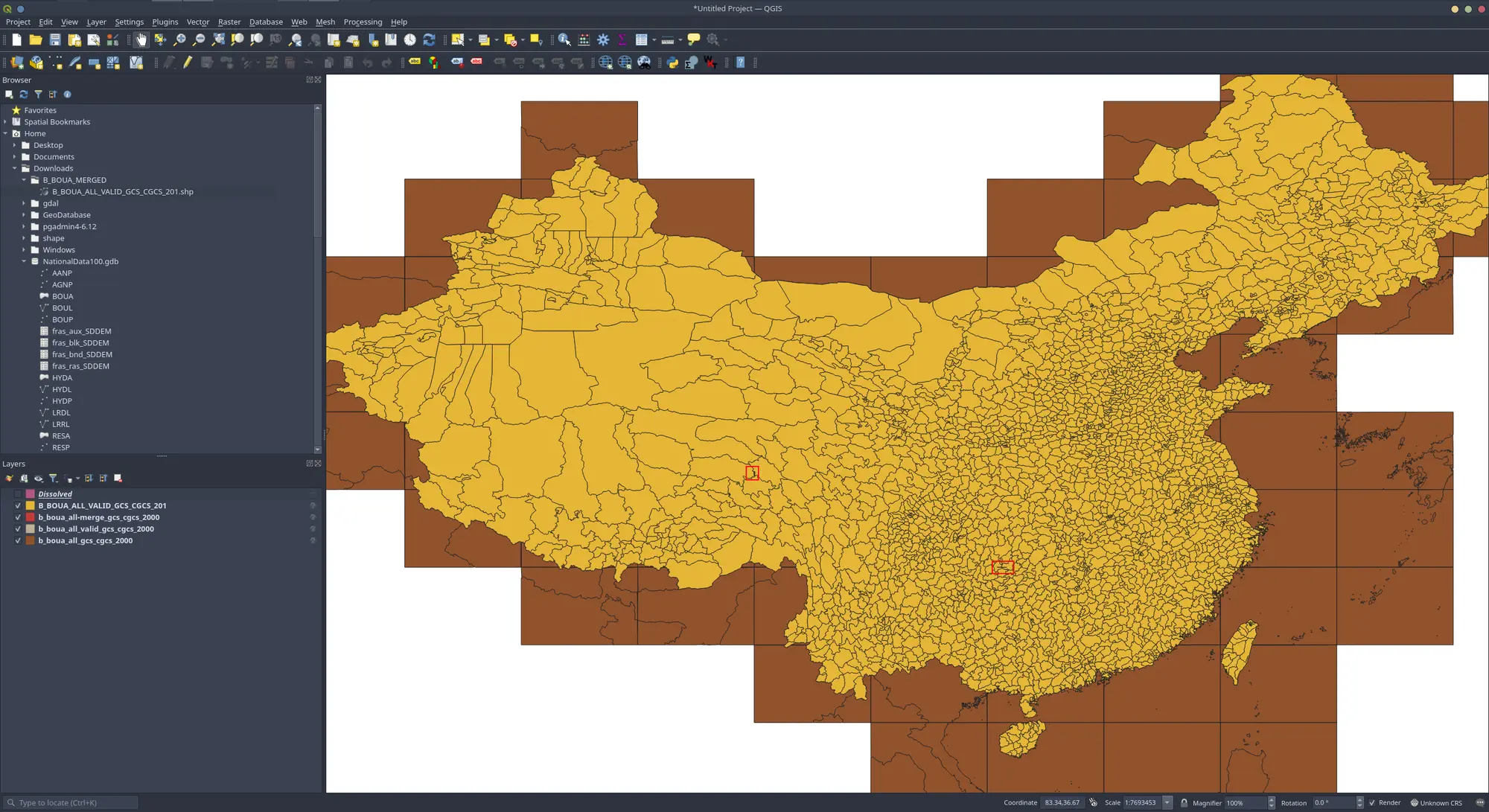
QGIS
WuKong
Source Code
小结
因做境界合并,开发了WuKong程序,但是其含义并不仅仅只是进行境界合并,他是一个基于国家开放的基础地理信息数据的(目前是基于1:100玩基础地理信息数据),可以进行归一、转换、释放的通用程序。
虽然目前仅完成了基础境界的合并(且存在瑕疵,但好歹也和QGIS的实现差不多不是),但这仅仅只是开始,还有更多的内容可以实现。
参考
全国地理信息资源目录服务系统(https://www.webmap.cn/)
数据来源于全国地理信息资源目录服务系统:www.webmap.cn
GB/T 13989-2012 国家基本比例尺地形图分幅和编号
1:1000000地形图的分幅
经度:72~138(E),43~53(11)
纬度:0~56(N),A~N(14)

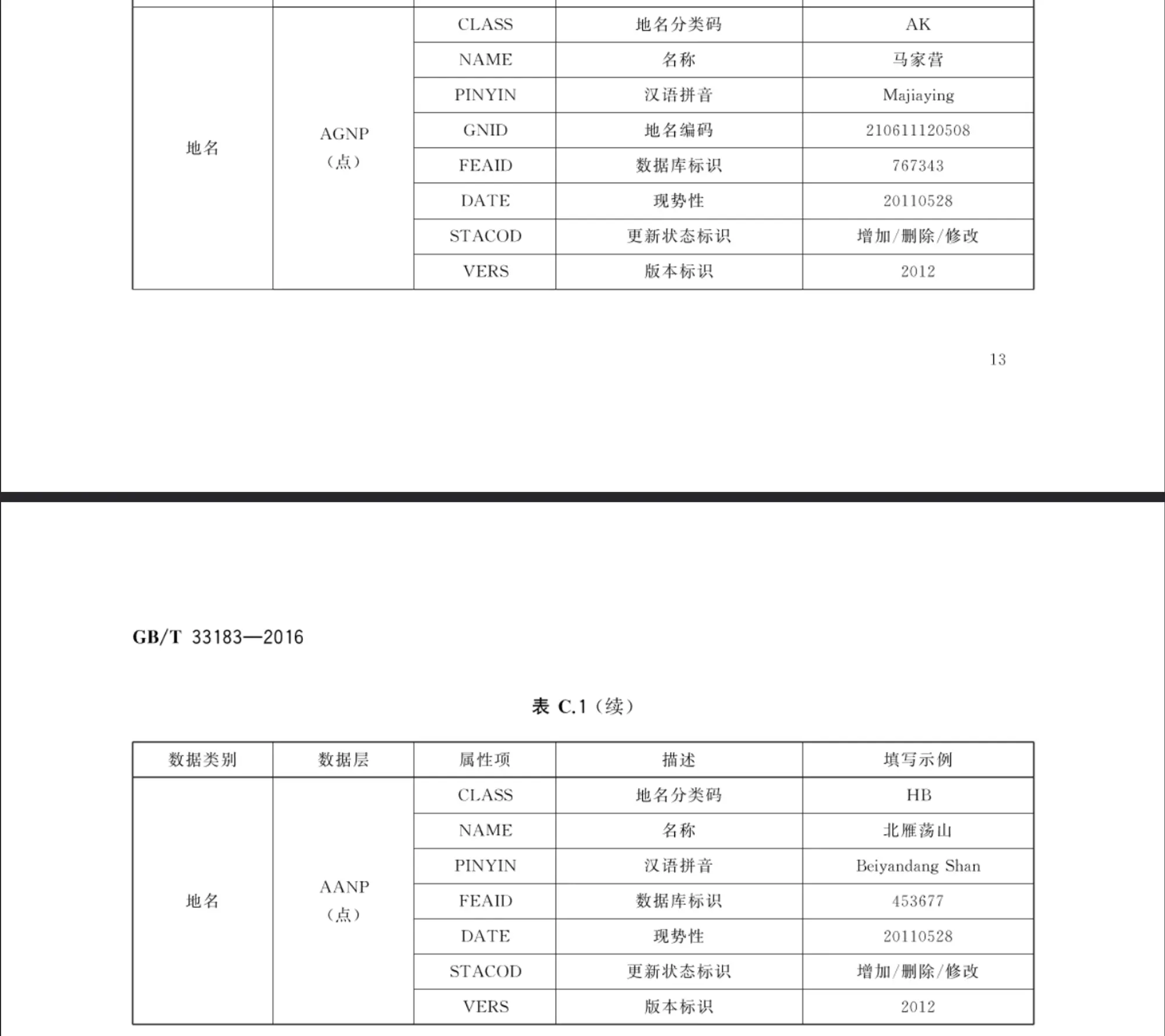
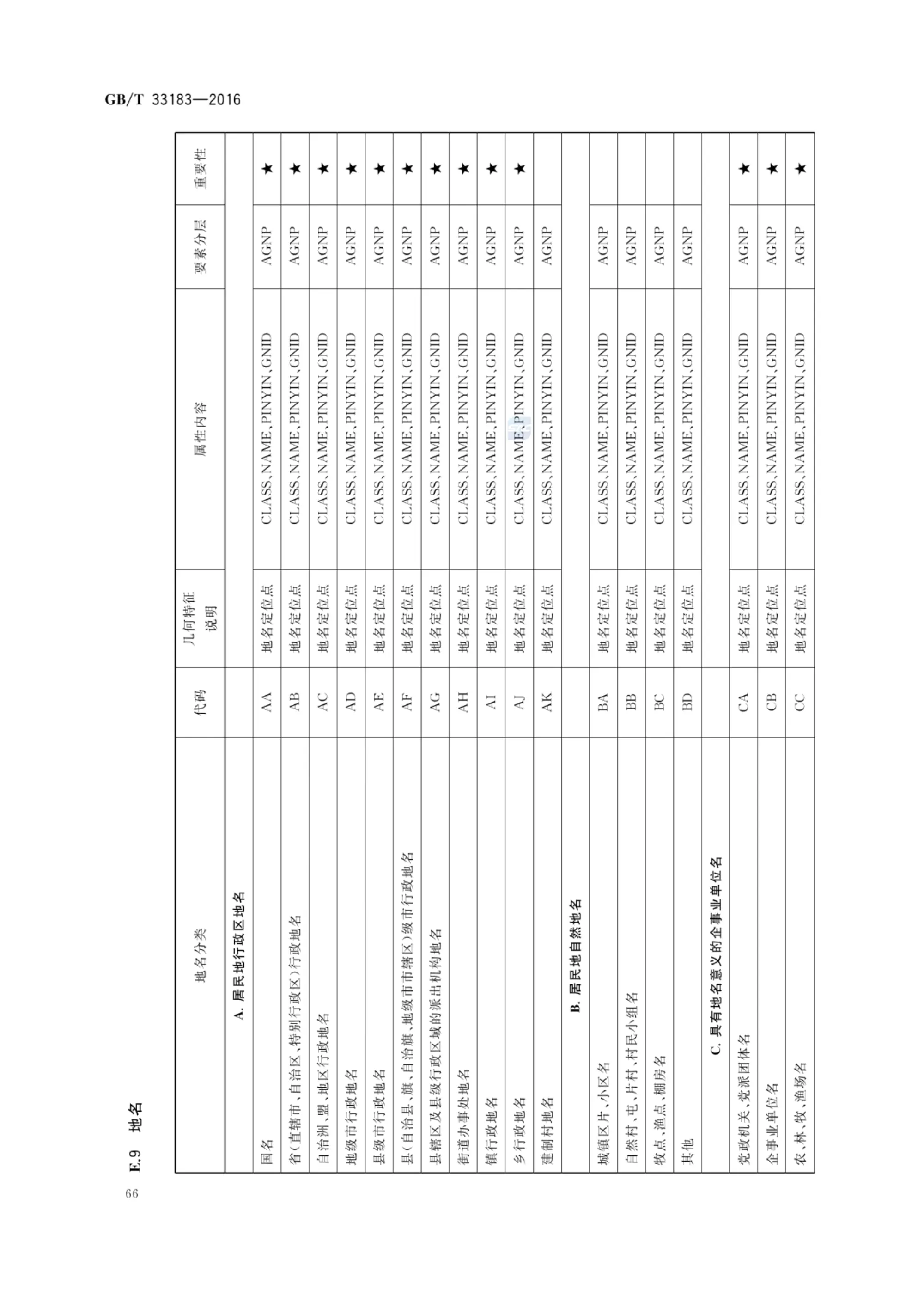
GB/T 33183-2016 基础地理信息 1:50 000地形要素数据规范
1:50000地形要素属性表结构
- 境界与政区
- 地名
1:50000地形要素数据要素内容与选取指标
走天涯徐小洋公众号
【资源分享】如何查找靠谱的国标,全文免费看!全文免费看!全文免费看!
GDAL
vector-openfilegdb
Vector Data Model - GDAL documentation
ESRI File Geodatabase (OpenFileGDB) - GDAL documentation
Java bindings - GDAL documentation
Overview (GDAL/OGR 3.5.0 Java bindings API)
Other
https://github.com/modood/Administrative-divisions-of-China